




Роботички фудбалери постају вештији, захваљујући методи учења Google DeepMind-а
Стручњаци из Google-овог одељења DeepMind применили су метод учења на миниатюрне роботе који би у будућности могли да се користе за обуку хуманоидних робота дизајнираних да помажу људима.
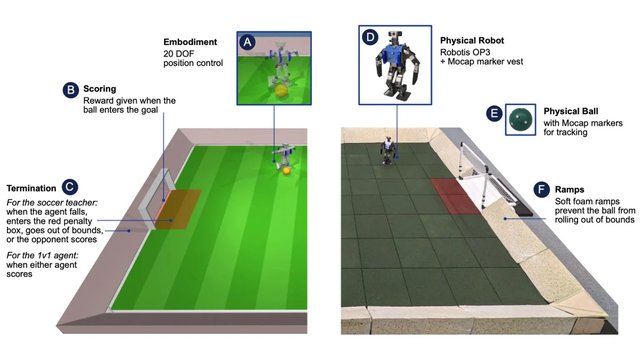
Годинама су истраживачи у области вештачке интелигенције и роботике настојали да створе генералну интелигенцију која ће омогућити роботима да се крећу у физичком свету са истим вештинама, агилношћу и разумевањем као животиње или људи. Развој, који је годинама у току, недавно је фокусиран на дубоко учење зајачањем (ДЛР). Прогрес њиховог рада био је приказан у фудбалској утакмици коју су играли роботи. Док су четвороноги роботи показали изузетну вештину у игрању фудбала и контроли топке, њихови двоноги колеги се и даље показују неуредно. Ово је првенствено због основних вештина на које се истраживачи морају усредсредити због стабилности и ограничења хардвера. ДЛР комбинује две стратегије учења како би се суочио са овим изазовима. Користећи овај приступ, истраживачи из Google DeepMind-а покушали су да науче јефтине миниатюрне роботе да играју фудбал и да се такмиче у утакмицама један на један. Резултати ових експеримената, који су се спроводили у симулираном и физичком окружењу, објављени су у научном часопису Science Robotics. Почетни фокус је био на две области: једна је била о томе како роботи могу да устану са земље, а друга је била о томе како могу да постигну голове против нетренираних противника. Учење подстицањем се показало ефикасним, јер су роботи брзо научили да устану, ходају, окрећу се и ударају прецизно, као и да се лако пребацују између ових акција. Ово је резимирано у студији Интересинг Енгинееринг-а. Поред тога, робот је био способан да блокира противнички удар и да предвиди правац кретања лопте. Стручњаци тврде да би ручно развијање ових вештина било непрактично, јер робот увек мора прилагодљиво да реагује на околности. Стручњаци су открили да је стратегија кретања развијена у симулираном окружењу лако пренета на стварне роботе. У експерименталним утакмицама, роботи обучени овом методом кретали су се 181 одсто брже, окретали 302 одсто брже, ударали лопту 34 одсто брже и устали 63 одсто брже након пада, у поређењу са уређајима који су играли само на основу скрипта са основним знањем. Истраживачи верују да то отвара пут за учење хуманоидним роботима како да се безбедно крећу и извршавају сложене акције у динамичном окружењу, што најављује нову еру у потенцијалу за помоћ роботима и сарадњу са људима.
Translation:
•
Translated by AI